觀察")
李想談VLA:我們走的是無(wú)人區(qū)
作者:
AO記者 李琳
2025-05-09 10:12

5月7日,理想汽車(chē)推出“理想AI Talk第二季”,理想汽車(chē)董事長(zhǎng)兼CEO李想分享了理想汽車(chē)對(duì)人工智能與VLA司機(jī)大模型的思考。
李想認(rèn)為AI工具分為三個(gè)層級(jí),分別是信息工具、輔助工具和生產(chǎn)工具。目前,大多數(shù)人將AI作為信息工具使用,但信息工具常伴隨大量無(wú)效信息、無(wú)效結(jié)果和無(wú)效結(jié)論,僅具參考價(jià)值。成為輔助工具后,AI可以提升效率,例如現(xiàn)在的輔助駕駛,但仍需人類(lèi)參與。
“我認(rèn)為Agent(智能體)是否智能,最重要的評(píng)判條件是它是否是個(gè)生產(chǎn)工具,它是否真正能替代我去完成專(zhuān)業(yè)的工作,它是否真的在產(chǎn)生有效的生產(chǎn)力、真正改變我們的工作的成果、減少我們的工作時(shí)長(zhǎng)。”李想表示,“只有當(dāng)人工智能變成生產(chǎn)工具,才是其真正爆發(fā)的時(shí)刻。就像人類(lèi)會(huì)雇用司機(jī),人工智能技術(shù)最終也會(huì)承擔(dān)類(lèi)似職責(zé),成為真正的生產(chǎn)工具。”
李想認(rèn)為,VLA(Vision-Language-Action Model,視覺(jué)語(yǔ)言行動(dòng)模型)對(duì)于理想汽車(chē)來(lái)說(shuō),是一個(gè)司機(jī)大模型,是一個(gè)讓AI像人類(lèi)司機(jī)一樣去工作的模型。

VLA的實(shí)現(xiàn)不是一個(gè)突變的過(guò)程,而是進(jìn)化的過(guò)程,經(jīng)歷了三個(gè)階段:
第一階段是“昆蟲(chóng)動(dòng)物智能”,為算法和高精地圖的輔助駕駛,2021年,理想汽車(chē)開(kāi)始了這一階段。“這一階段需要通過(guò)機(jī)器學(xué)習(xí)感知,配合規(guī)則算法,需要依賴(lài)高精地圖,就像螞蟻行動(dòng)和完成任務(wù)的方式。”李想分析,“這一階段的效率比較低,規(guī)則算法的整個(gè)規(guī)模只有幾百萬(wàn)參數(shù),那么小的腦子,完成復(fù)雜的事基本不可能。”
第二階段為“哺乳動(dòng)物智能”,為端到端+VLM(Vision Language Model,視覺(jué)語(yǔ)言模型)輔助駕駛。理想汽車(chē)自2023年起研究,并于2024年正式推送的端到端+VLM。“端到端比較像哺乳動(dòng)物的智能,比如馬戲團(tuán)的動(dòng)物向人類(lèi)學(xué)習(xí)騎自行車(chē),端到端就是學(xué)習(xí)人類(lèi)的各種行為開(kāi)車(chē)。”李想表示,“但端到端對(duì)物理世界并不理解,它可以應(yīng)付大部分泛化問(wèn)題,但應(yīng)對(duì)沒(méi)有學(xué)過(guò)的、特別復(fù)雜的狀況就會(huì)遇到問(wèn)題。所以我們要配合VLM,但VLM也只能起到非常有限的輔助作用。”
第三階段為“人類(lèi)智能”階段。“它會(huì)像人類(lèi)一樣,利用3D視覺(jué)和2D的組合去看整個(gè)真實(shí)的物理世界,它能讀懂導(dǎo)航軟件,而不是像VLM那樣,只看到一張圖片。他擁有自己的整個(gè)腦系統(tǒng),不但能看到物理世界,還能夠理解物理世界。它有它的language(語(yǔ)言),有它的CoT(思維鏈),具備推理能力,可以像人類(lèi)一樣執(zhí)行行動(dòng)。執(zhí)行一些復(fù)雜動(dòng)作,在汽車(chē)自動(dòng)駕駛領(lǐng)域稱(chēng)之為VLA的司機(jī)大模型。”李想解釋。

VLA的訓(xùn)練將經(jīng)歷分為預(yù)訓(xùn)練、后訓(xùn)練和強(qiáng)化訓(xùn)練三個(gè)環(huán)節(jié)。
預(yù)訓(xùn)練相當(dāng)于人類(lèi)學(xué)習(xí)物理世界和交通領(lǐng)域的常識(shí),通過(guò)大量高清2D和3D Vision(視覺(jué))數(shù)據(jù)、交通相關(guān)的Language(語(yǔ)言)語(yǔ)料,以及與物理世界相關(guān)的VL(Vision-Language,視覺(jué)和語(yǔ)言)聯(lián)合數(shù)據(jù),訓(xùn)練出云端的VL基座模型,并通過(guò)蒸餾轉(zhuǎn)化為在車(chē)端高效運(yùn)行的端側(cè)模型。
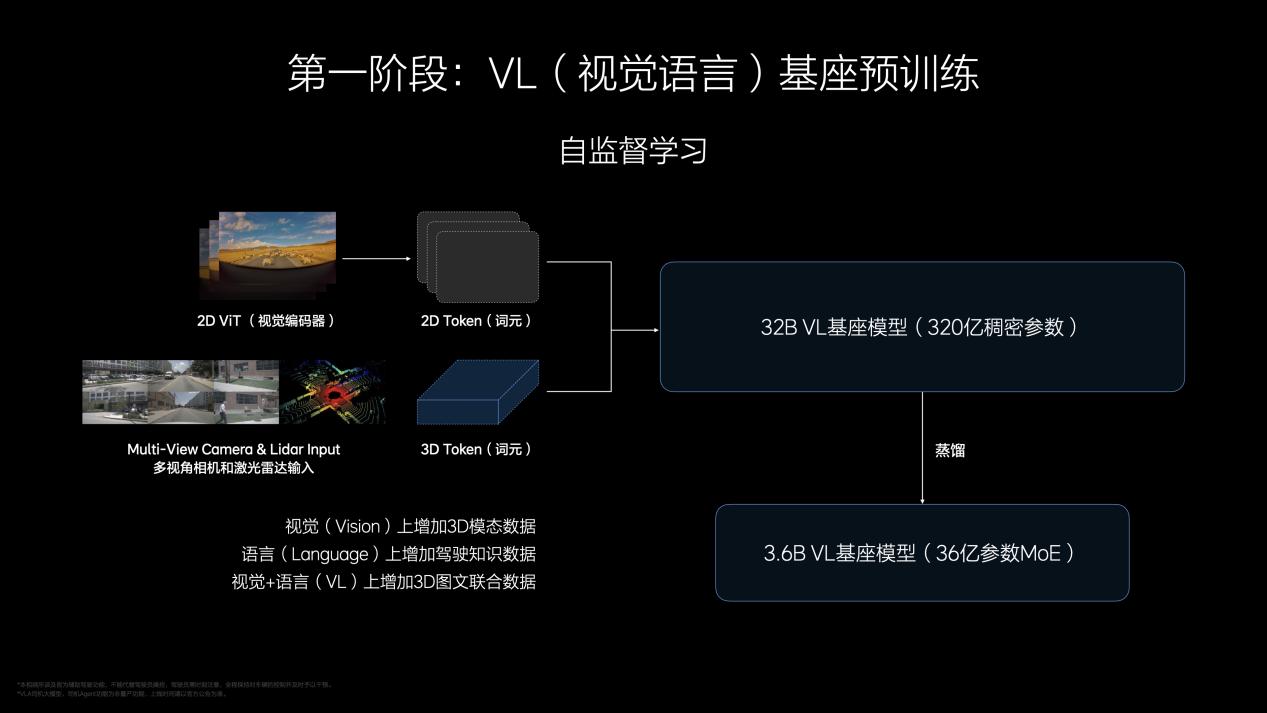
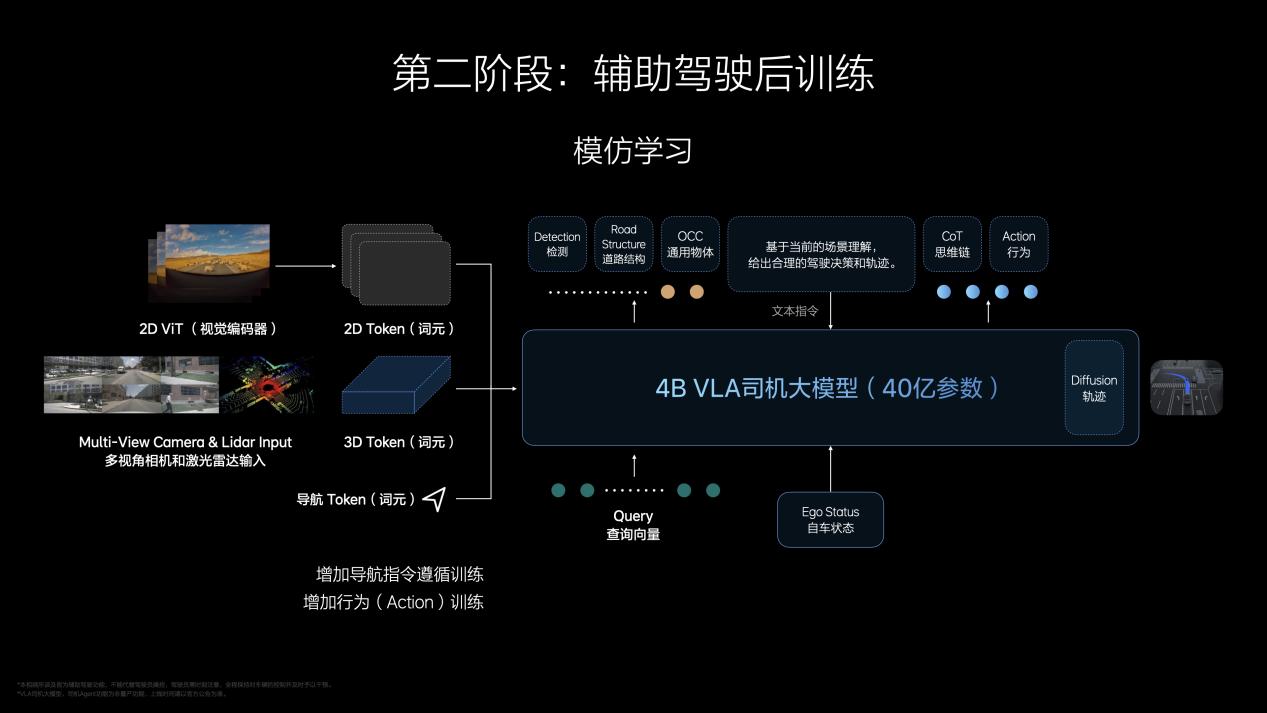
后訓(xùn)練相當(dāng)于人類(lèi)去駕校學(xué)習(xí)開(kāi)車(chē)的過(guò)程。隨著Action(動(dòng)作)數(shù)據(jù)的加入——即對(duì)周?chē)h(huán)境和自車(chē)駕駛行為的編碼,VL基座變?yōu)閂LA司機(jī)大模型。得益于短鏈條的CoT,以及Diffusion擴(kuò)散模型對(duì)于他車(chē)軌跡和環(huán)境的預(yù)測(cè),VLA具備實(shí)時(shí)性的特點(diǎn),實(shí)現(xiàn)了在復(fù)雜交通環(huán)境中的博弈能力。
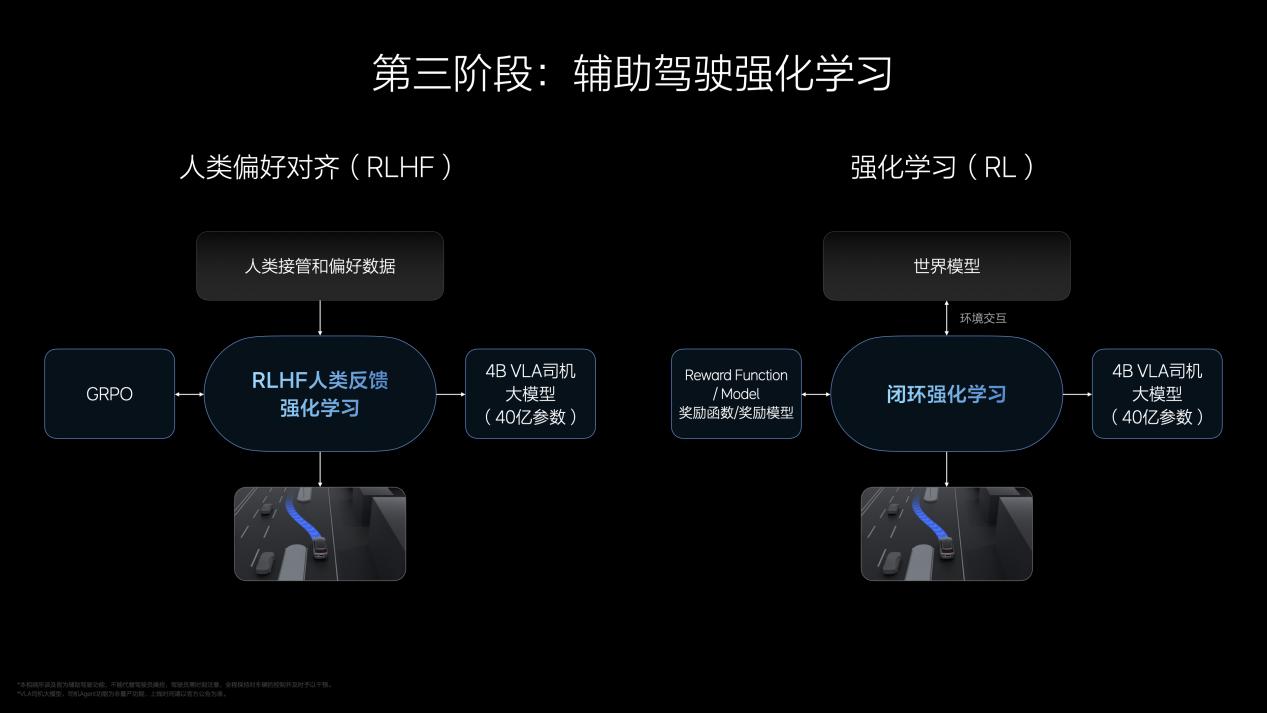
強(qiáng)化訓(xùn)練類(lèi)似于人類(lèi)在社會(huì)中實(shí)際開(kāi)車(chē)練習(xí),目標(biāo)是讓VLA司機(jī)大模型更加安全、舒適,對(duì)齊人類(lèi)價(jià)值觀,甚至超越人類(lèi)駕駛水平。強(qiáng)化訓(xùn)練包含兩部分:一是通過(guò)RLHF(Reinforcement Learning from Human Feedback,基于人類(lèi)反饋的強(qiáng)化學(xué)習(xí))完成安全對(duì)齊,使模型遵守交通規(guī)則,貼合中國(guó)用戶(hù)的駕駛習(xí)慣;二是將純強(qiáng)化學(xué)習(xí)模型放入世界模型中訓(xùn)練,提升舒適性,避免碰撞事故,遵守交通規(guī)則。
既然VLA的能力如此之高,可否越過(guò)端到端直接實(shí)現(xiàn)?“沒(méi)有可能。”李想打了個(gè)形象的比喻,一般人們可能吃到第十個(gè)包子就飽了,但沒(méi)有辦法跳過(guò)前面的包子直接吃到第十個(gè)包子。
據(jù)李想介紹,VLA司機(jī)大模型以“司機(jī)Agent(智能體)”的產(chǎn)品形態(tài)呈現(xiàn),部署至車(chē)端運(yùn)行。李想認(rèn)為VLA能夠解決全自動(dòng)駕駛,將成為現(xiàn)階段能力最強(qiáng)的架構(gòu),甚至有機(jī)會(huì)超越人類(lèi)開(kāi)車(chē)的能力。
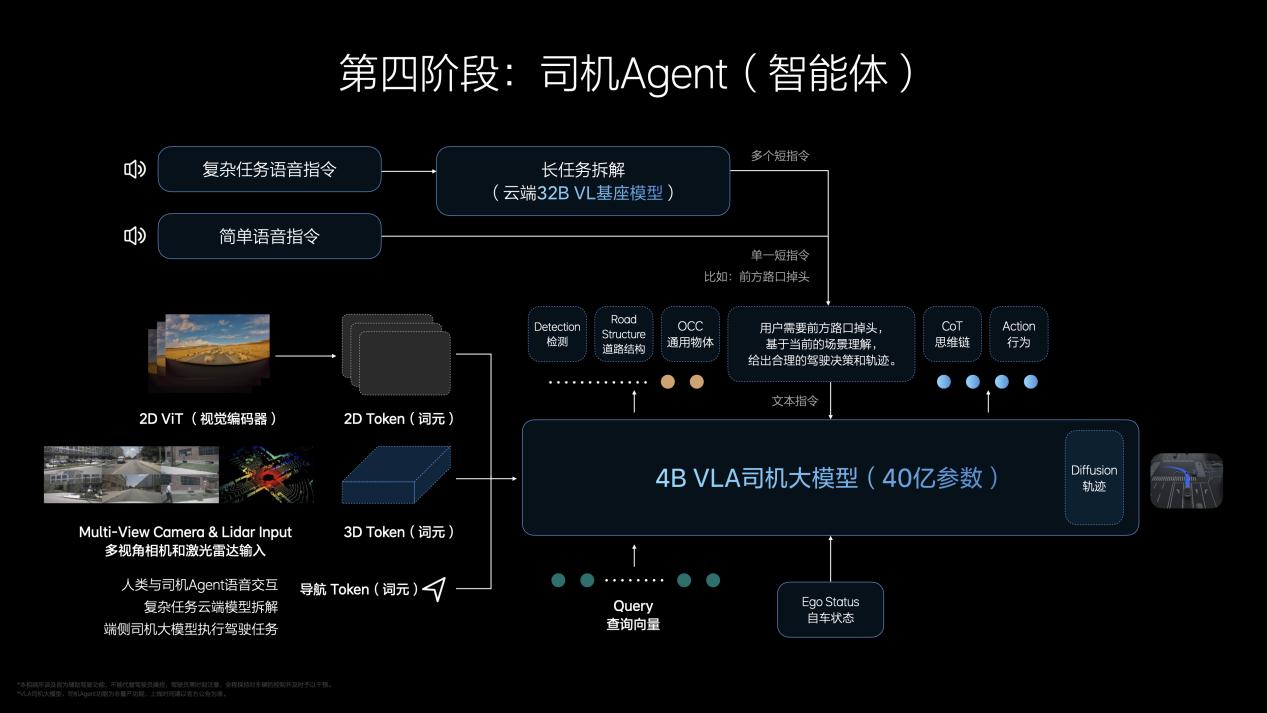
不過(guò)能力越強(qiáng),責(zé)任越大。李想認(rèn)為判斷司機(jī)Agent是不是個(gè)好司機(jī)與評(píng)判員工的標(biāo)準(zhǔn)相同:“第一,看他的專(zhuān)業(yè)能力;第二看他的職業(yè)性;第三看他與別人構(gòu)建信任的能力。”VLA司機(jī)大模型提升了專(zhuān)業(yè)能力,VLA通過(guò)理解自然語(yǔ)言、具備記憶能力提升了構(gòu)建信任的能力,司機(jī)Agent職業(yè)能力的實(shí)現(xiàn)則依靠超級(jí)對(duì)齊。
為了保障VLA司機(jī)大模型能夠?qū)崿F(xiàn)職業(yè)司機(jī)般的安全,理想汽車(chē)在強(qiáng)化訓(xùn)練環(huán)節(jié)投入大量資源,并于2024年底組建超過(guò)100人的超級(jí)對(duì)齊團(tuán)隊(duì),相當(dāng)于為司機(jī)Agent注入職業(yè)素養(yǎng)。
在談到VLA訓(xùn)練過(guò)程中,哪個(gè)步驟最難時(shí),李想坦言無(wú)法預(yù)測(cè)。“因?yàn)槲覀兦懊鏇](méi)有任何人走過(guò)這條路。DeepSeek也沒(méi)走過(guò)這條路,OpenAI也沒(méi)有走過(guò)這條路,谷歌、Waymo也沒(méi)有走過(guò)這條路。我們其實(shí)走的是一個(gè)無(wú)人區(qū)。”
創(chuàng)業(yè)路上的苦多于甜,不過(guò)李想表示將會(huì)保持高中時(shí)的思維方式:“遇到問(wèn)題,解決問(wèn)題,解決別人不愿解決的問(wèn)題,解決消費(fèi)者最大的問(wèn)題。”
觀察")
商務(wù)合作
電話(huà):13051199966
地址:北京市朝陽(yáng)區(qū)清林路1號(hào)世茂奧臨花園
版權(quán)所有 © 1999-2018 北京云聯(lián)文化傳播有限公司
網(wǎng)站建設(shè):中企動(dòng)力 北京